1、方法1:设置等待时间有一些网站的防范措施可能会因为你快速提交表单而把你当做机器人爬虫,比如说以非常人的速度下载图片,登录网站,爬取信息。常见的设置等待时间有两种,一种是显性等待时间(强制停几秒),一种是隐性等待时间(看具体情况,比如根据元素加载完成需要时间而等待)

2、方法2:修改请求头识别你是机器人还是人类浏览器浏览的飒劐土懿重要依据就是User-Agent,比如人类用浏览器浏览就会使这个样子的User-Agent:’Mozil造婷用痃la/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36’这里拿urllib2来说,默认的User-Agent是Python-urllib2/2.7,所以要进行修改。
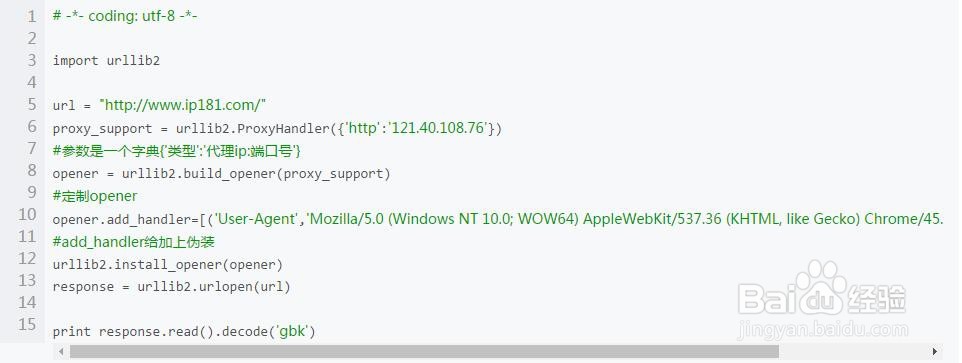
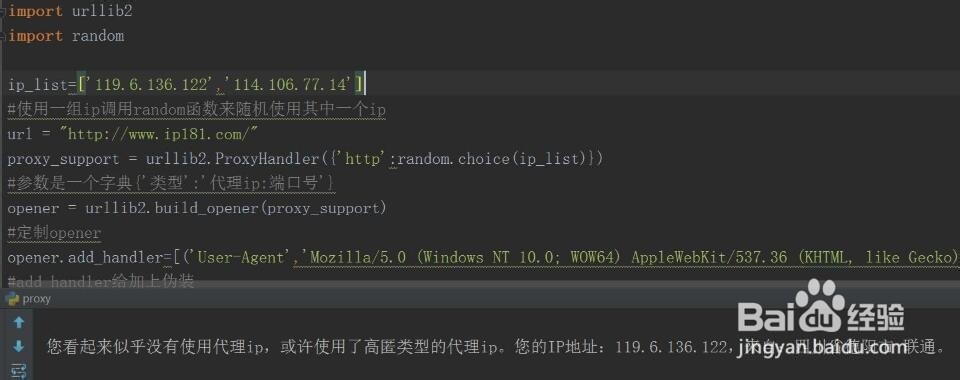
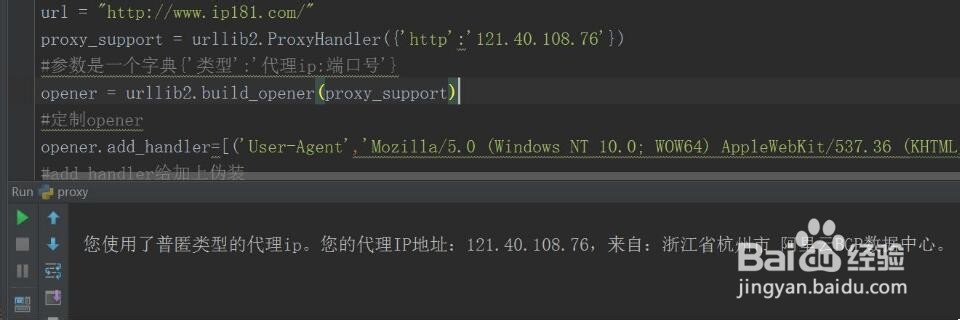
3、方法3:采用代理ip当自己的ip被网站封了之后,只能采取换代理ip的方式进行爬取,所以,我建议,每次爬取的时候尽量用代理来爬,封了代理,还有代理,可别拿代理去黑学校网站。
4、方法4:避开不可见元素陷阱自己爬着爬着就把隐藏元素都爬出来了,你说你自己是不是爬虫吧,这是网站给爬虫的陷阱,只要发现,立马封IP,所以请查看一下元素再进行爬取!比如说这个网址,一个简单的登录页面,从审查元素中我们可以看到有一些元素是不可见的!
5、方法5:采用分布式爬取分布式爬取,针对比较大型爬虫系蕙蝤叼翕统,实现步骤如下所示1.基本的http抓取工具,如scrapy2.避免重复抓取网页,如Bloom Filter3.维护一个所有集群机器能够有效分享的分布式队列4.将分布式队列和Scrapy结合5.后续处理,网页析取(python-goose),存储(Mongodb)