1、点击开始--运行,输入cmd命令,打开windows命令行窗口

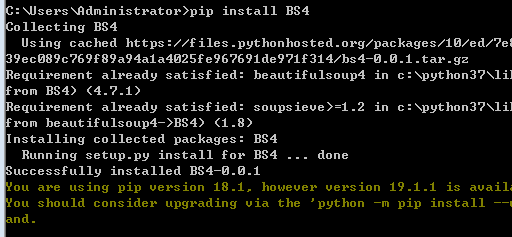
2、使用pip安装BeautifulSoup包pip install BS4
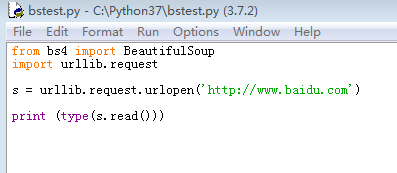
3、打开python开发工具IDLE,新建‘bstest.py’文件,并代码如下:from bs4 import BeautifulSoupimport urllib.requests = urllib.request.urlopen('http://www.baidu.com')print (type(s.read()))
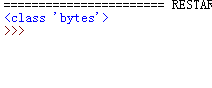
4、F5运行代码,打印出返回结果类型,为bytes
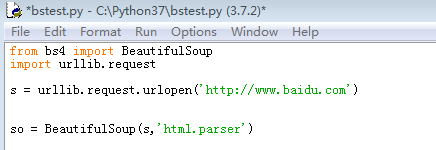
5、修改代码,将响应传入创建一个BeautifulSoup对象,这样就可以解析了,注意不要使用read方法,代码剧安颌儿如下:from bs4 import BeautifulSoupimport urllib.requests = urllib.request.urlopen('http://www.baidu.com')so = BeautifulSoup(s,'html.parser')
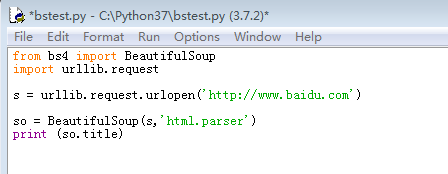
6、使用创建的BeautifulSoup对象打印网页的title,代码如下:from bs4 import BeautifulSoupimport urllib.requests = urllib.request.urlopen('http://www.baidu.com')so = BeautifulSoup(s,'html.parser')print (so.title)
7、F5运行代码打印出网页的title,正确解码成中文,这就是beautifulsoup的魅力

