1、 1、创建
在Spark SQL中SparkSession是创建DataFrame和执行SQL的入口,创建DataFrame有三种方式:通过Spark的数据源进行创建;从一个存在的RDD进行转换;还可以从Hive Table进行查询返回。
1)从Spark数据源进行创建
(1)查看Spark数据源进行创建的文件格式

2、(2)读取json文件创建DataFrame

3、(3)展示结果

4、2)从RDD进行转换
5、3)从Hive Table进行查询返回
6、2、 SQL风格语法(主要)
1)创建一个DataFrame

7、2)对DataFrame创建一个临时表
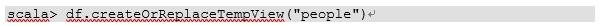
8、3)通过SQL语句实现查询全表

9、4)结果展示

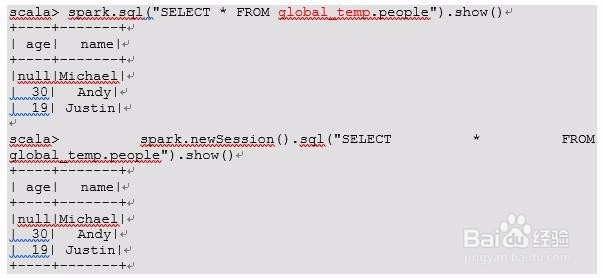
10、注意:普通临时表是Session范围内的,如果想应用范围内有效,可以使用全局临时表。使用全局临时表时需要全路径访问,如:global_temp.people
11、5)对于DataFrame创建一个全局表
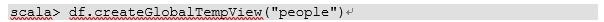
12、6)通过SQL语句实现查询全表
13、3、 DSL风格语法(次要)
1)创建一个DataFrame

14、2)查看DataFrame的Schema信息

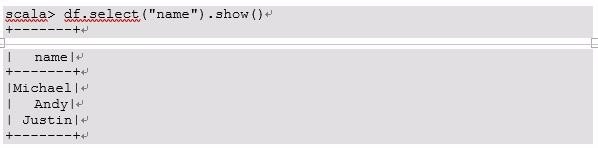
15、3)只查看”name”列数据
16、4)查看”name”列数据以及”age+1”数据

17、5)查看”age”大于”21”的数据

18、6)按照”age”分组,查看数据条数

