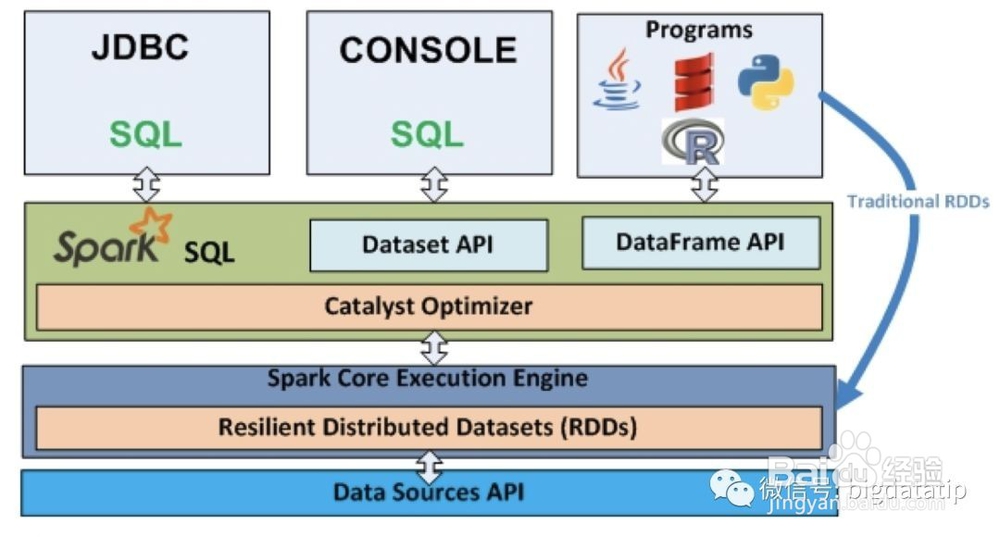
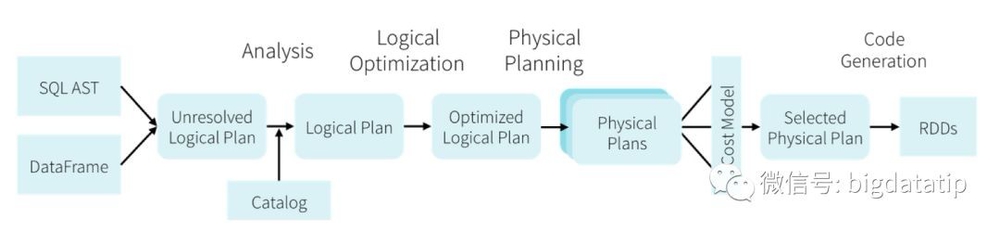
1、依赖Hive Metastore和Hive SerDe(用于兼容现有的各种Hive存储格式)。Spark SQL在Hive兼容层面仅依赖HQL parser、Hive Metastore和Hive SerDe。也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。执行计划生成和优化都由Catalyst负责。借助Scala的模式匹配等函数式语言特性,利用Catalyst开发执行计划优化策略比Hive要简洁得多。
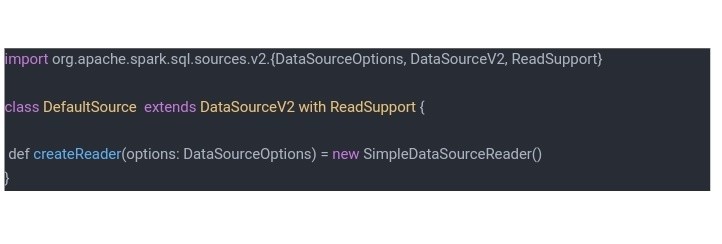
2、 Dataframe/Dataset也是分布式数据集,但与RDD不同的是其带有schema信息,类似一张表格。

3、 Dataset是在spark1.6引入的,目的是提供像RDD一样的强类型、使用强大的lambda函数,同时使用spark sql的优化执行引擎。到spark2.0以后,DataFrame变成类型为Row的Dataset。

4、 要先声明构建SQLContext或者SparkSession,这个是SparkSQL的编码入口。早起的版本使用的是SQLContext或者HiveContext,spark2以后,建议使用的是SparkSession。
5、 thriftserver jdbc/odbc的实现类似于hive1.2.1的hiveserver2,可以使用spark的beeline命令来测试jdbc server。