1、找到你要获取页面信息的链接,这里以一本图书为例来说明
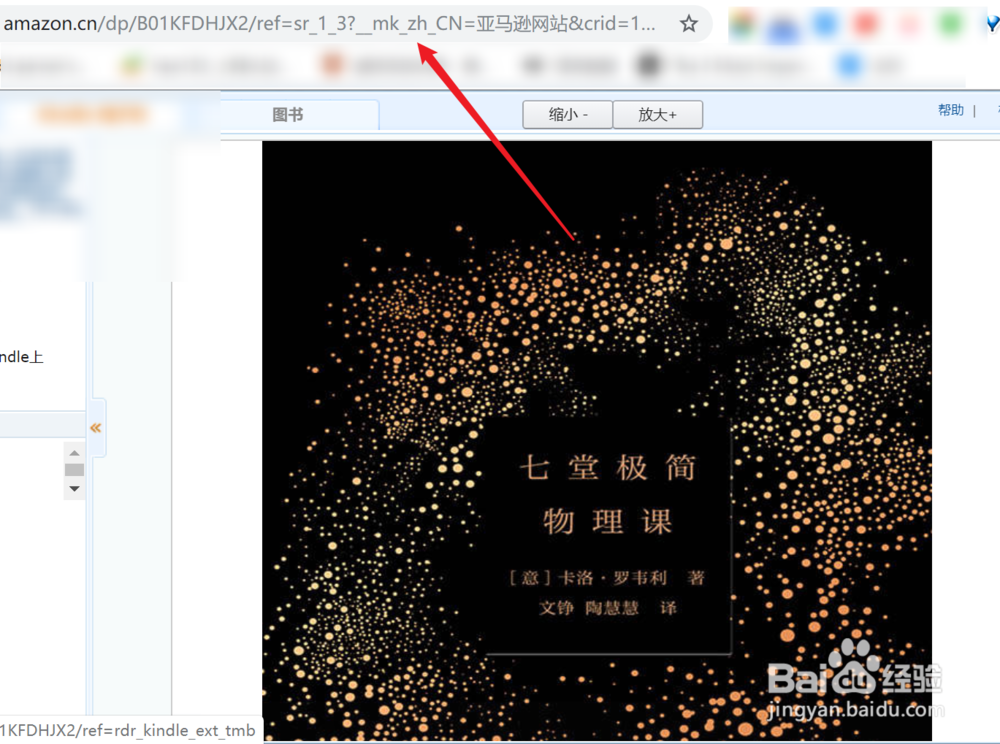
2、复制它的链接

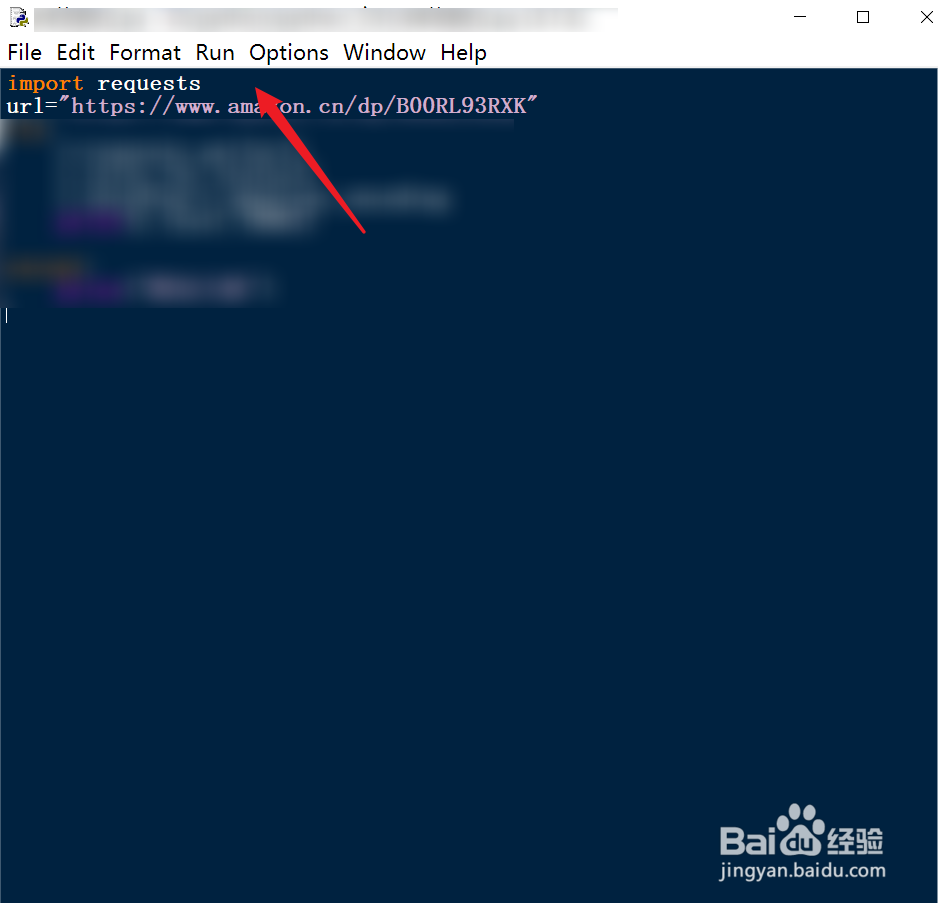
3、导入requests库,获取相应链接的返回信息。
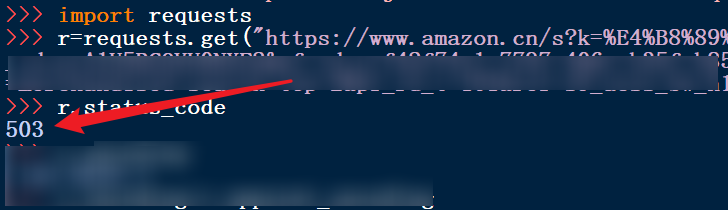
4、输入状态码,返回相应的返回状态。返回的状态如果是200,这说明访问成功。否则,返回失败,这里是503,说明访问失败
5、根据返回的信息判断可能是由于访问进行限制。接受的是由于浏览器发出的http请求。所以通过网站访问的http的头部判断请求

6、服务器判断出访问是由于python的requests库的程序的进行的。因此,修改访问头部的信息,模拟浏览器访问状态。
7、首先构造一个字典类型,修改 user-agent的信息
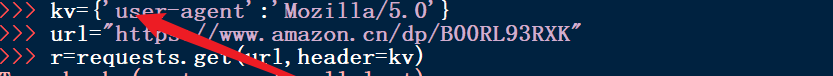
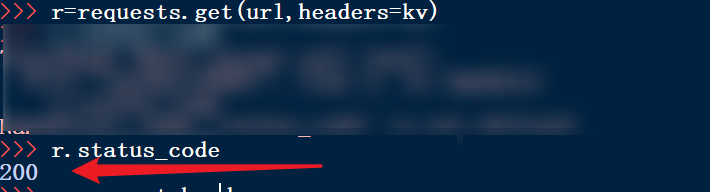
8、重新提交访问请求

9、再次检查访问状态。下图说明访问成功
10、获取访问的信息就可以了

