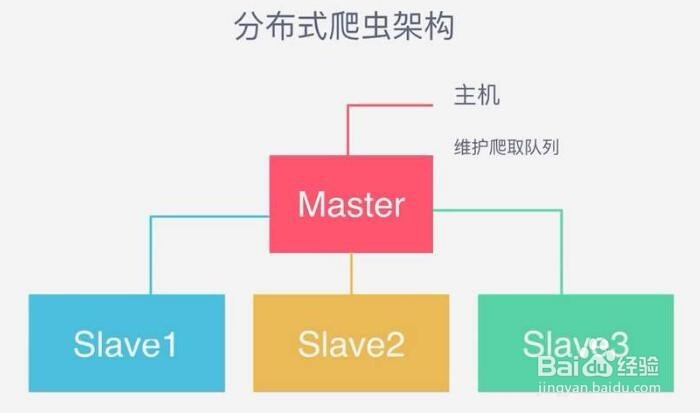
1、URL管理
首先url管理器添加了新的url到待爬取集合中,判断了待添加的url是否在容器中、是否有待爬取的url,并且获取待爬取的url,将url从待爬取的url集合移动到已爬取的url集合。
页面下载
下载器将接收到的url传给互联网,互联网返回html文件给下载器,下载器将其保存到本地,一般的会对下载器做分布式部署,一个是提交效率,再一个是起到请求代理作用。
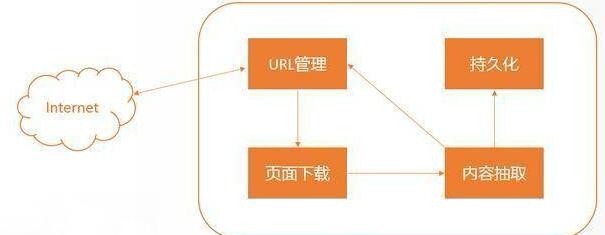
2、内容提取
页面解析器主要完成的是从获取的html网页字符串中取得有价值的感兴趣的数据和新的url列表。数据抽取比较常用的手段有基于css选择器、正则表达式、xpath的规则提取。一般提取完后还会对数据进行一定的清洗或自定义处理,从而将请求到的非结构数据转化为我们需要的结构化数据。
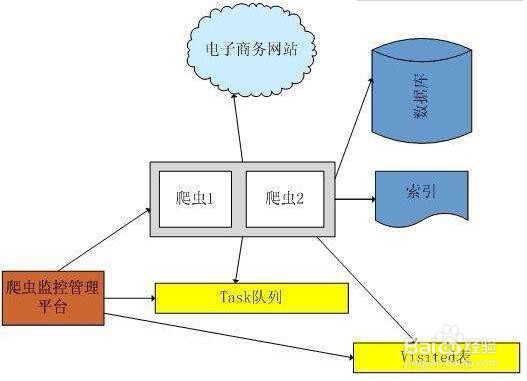
3、数据保存
数据保存到相关的数据库、队列、文件等方便做数据计算和与应用对接。
爬虫采集成为很多公司企业个人的需求,但正因为如此,反爬虫的技术也层出不穷,像时间限制、IP限制、验证码限制等等,都可能会导致爬虫无法进行,所以也出现了很多像代理IP、时间限制调整这样的方法去解决反爬虫限制,当然具体的操作方法需要你针对性的去研究。兔子动态IP软件可以实现一键IP自动切换,千万IP库存,自动去重,支持电脑、手机多端使用。